New Feature: Native Data Types
We are excited to announce the release of our new Native Data Types feature, designed to streamline data type propagation from source to storage.
We are excited to announce the release of our new Native Data Types feature, designed to streamline data type propagation from source to storage. This enhancement ensures that data types are automatically preserved throughout your data pipeline, reducing manual intervention and minimizing errors.
Key Benefits:
- Automatic Data Type Preservation: Source data types are respected automatically, eliminating the need for manual adjustments in Storage.
- Simplified Transformations: With read-only data access, there's no need for casting, making data operations smoother and more streamlined.
- Flexible Setup: Users can decide whether data types should be automatically fetched for each configuration when creating a table.
- Improved Workspace Loading: Loading data into a workspace is significantly faster than loading into a table without native data types, eliminating the need for additional casting.
How It Works:
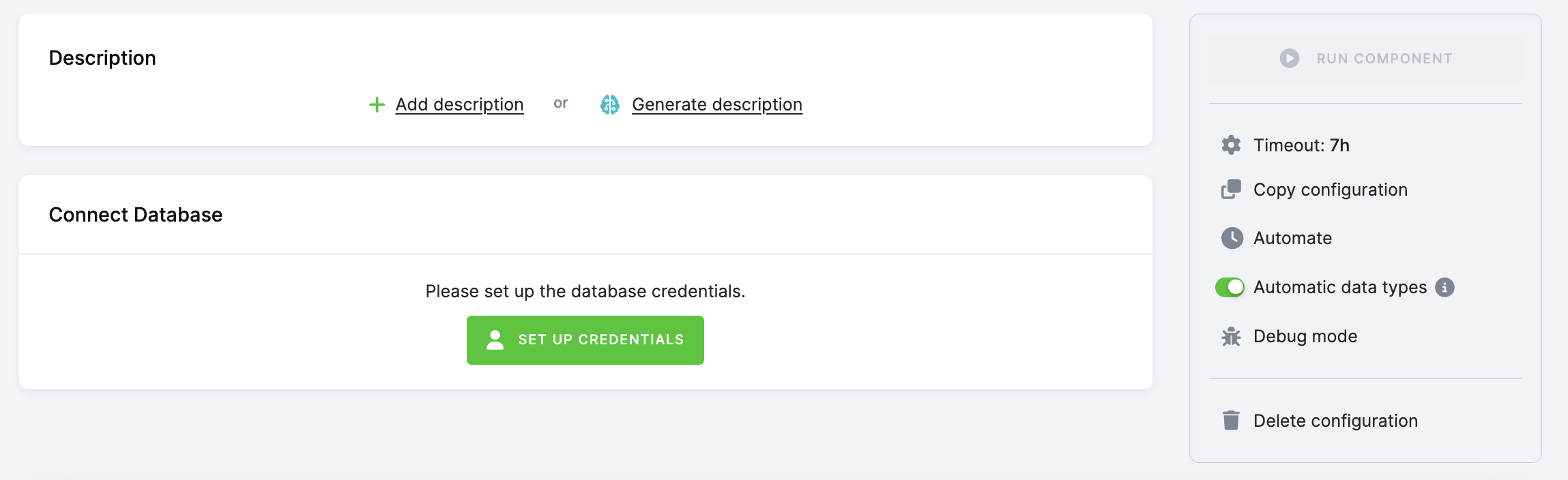
By default, with this feature ON, all new tables are created as typed tables if the component supports it. Non-Typed tables are labeled in the Storage UI with the label: NON-TYPED.
You can configure the data type behavior in the UI component configuration settings. If the component supports it, you will see Automatic data types in the right menu, which can be switched ON and OFF.
- When enabled: The component creates a typed table using data types from the source (e.g., DATETIME, BOOLEAN).
- When disabled: A typed table is created with all columns as VARCHAR, and data types are stored as metadata.
For a comprehensive understanding of this feature and detailed instructions, please refer to our Native Data Types documentation.
We believe this feature will significantly enhance your data processing experience by ensuring data integrity and reducing the need for manual data type management.
Give it a try and share your feedback! 🎉